Как один отчёт в 1С «съел» 500 ГБ tempdb и чуть не положил SQL Server
Разбор инцидента в связке 1С и SQL Server: почему один тяжёлый отчёт раздул tempdb до сотен гигабайт и как это удалось локализовать.

Оптимизация 1С-систем редко бывает линейной задачей. Чаще это цепочка гипотез, быстрых проверок и ложных следов. В этом случае всё началось с жалоб пользователей: один из отчётов либо выполнялся мучительно долго, либо завершался ошибкой ещё до построения результата.
Текст ошибки выглядел буднично: SQL Server не мог выделить новую страницу в базе TEMPDB из-за нехватки места. На первый взгляд это походило на обычное переполнение диска, но уже первые проверки показали, что проблема сидит глубже и связана не с железом как таковым, а с поведением самого отчёта.

С чего началась диагностика
Система была классической: 1С:Предприятие, Microsoft SQL Server и единый сервер приложений и СУБД. По базовым метрикам картина не выглядела катастрофической: процессор не был забит под 100%, память держалась на высоком, но ещё объяснимом уровне. Зато диск с системным томом оказался почти полностью заполнен.
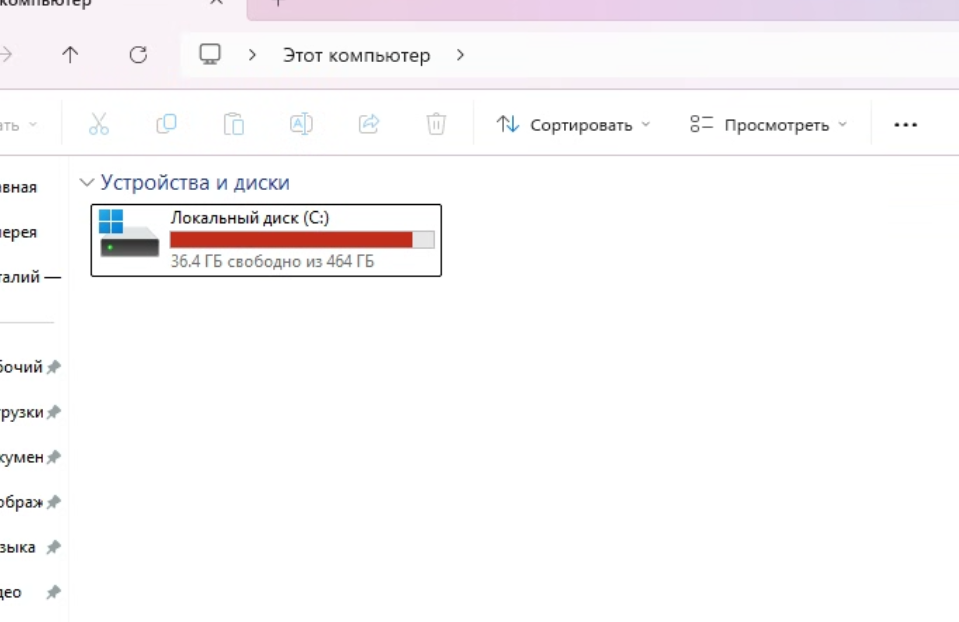
Дополнительная проверка через диспетчер задач подтвердила, что основную нагрузку создают процессы SQL Server и rphost. В момент построения отчёта SQL Server активно расходовал память и держал диск в почти постоянной работе, что хорошо укладывалось в гипотезу о лавинообразном росте временных структур.
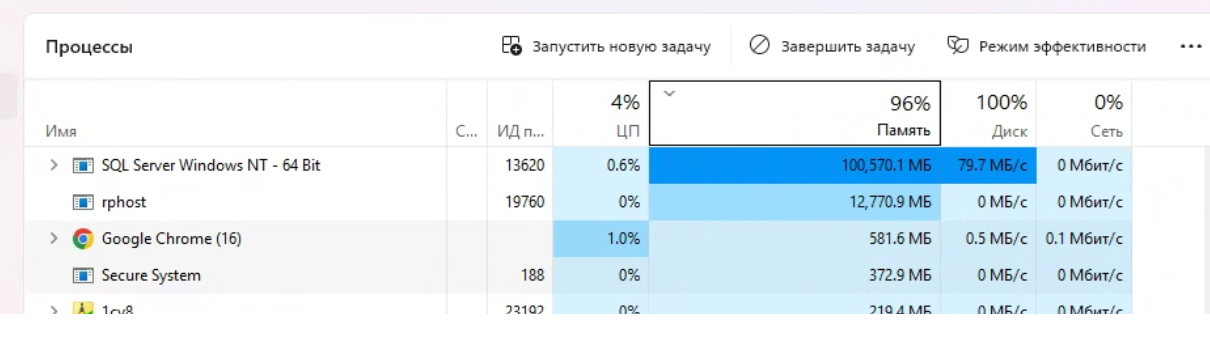
Что происходило внутри tempdb
Следующий шаг был очевиден: посмотреть, какие объекты в tempdb занимают максимум памяти и буферного кэша. Для этого достаточно простого запроса к системным представлениям SQL Server.
SELECT
DB_NAME(b.database_id) AS DBName,
OBJECT_NAME(p.object_id, b.database_id) AS ObjectName,
COUNT(*) * 8 / 1024 AS SizeMB
FROM sys.dm_os_buffer_descriptors AS b
JOIN sys.allocation_units AS a
ON b.allocation_unit_id = a.allocation_unit_id
JOIN sys.partitions AS p
ON a.container_id = p.hobt_id
WHERE b.database_id = DB_ID()
GROUP BY b.database_id, p.object_id
ORDER BY SizeMB DESC;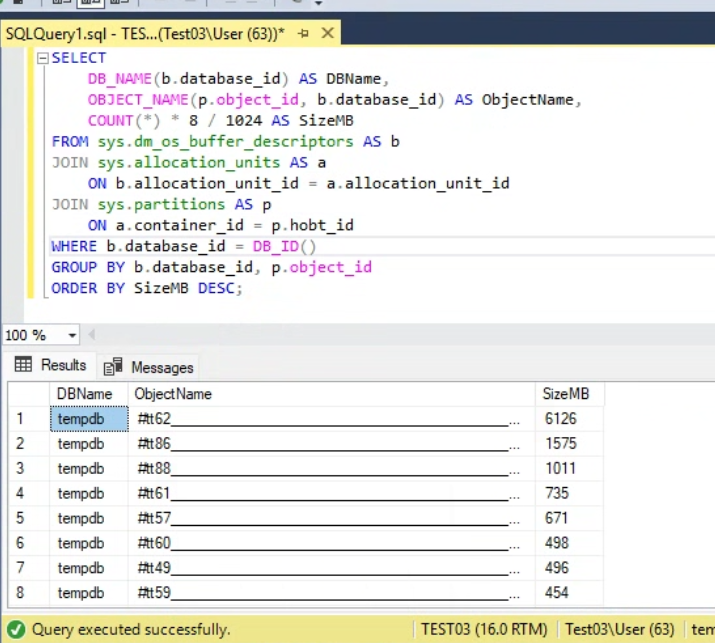
Результат показал характерную картину: tempdb был заполнен наборами временных объектов с техническими именами вида `#...`. Это сразу сузило область поиска. Значит, проблема не в общем росте пользовательской базы, а в промежуточных таблицах, сортировках или служебных структурах, которые создавались по ходу выполнения отчёта.
Поиск конкретной сессии
После этого задача сводилась к одному: найти сессию, которая раздувает tempdb сильнее остальных. Для этого удобно смотреть использование пользовательских и внутренних объектов по активным сессиям.
SELECT
s.session_id,
s.login_name,
r.status,
r.command,
r.wait_type,
(su.user_objects_alloc_page_count * 8 / 1024) AS UserMB,
(su.internal_objects_alloc_page_count * 8 / 1024) AS InternalMB
FROM sys.dm_exec_sessions s
JOIN sys.dm_exec_requests r ON s.session_id = r.session_id
JOIN sys.dm_db_session_space_usage su ON s.session_id = su.session_id
WHERE su.user_objects_alloc_page_count > 0
OR su.internal_objects_alloc_page_count > 0
ORDER BY UserMB DESC;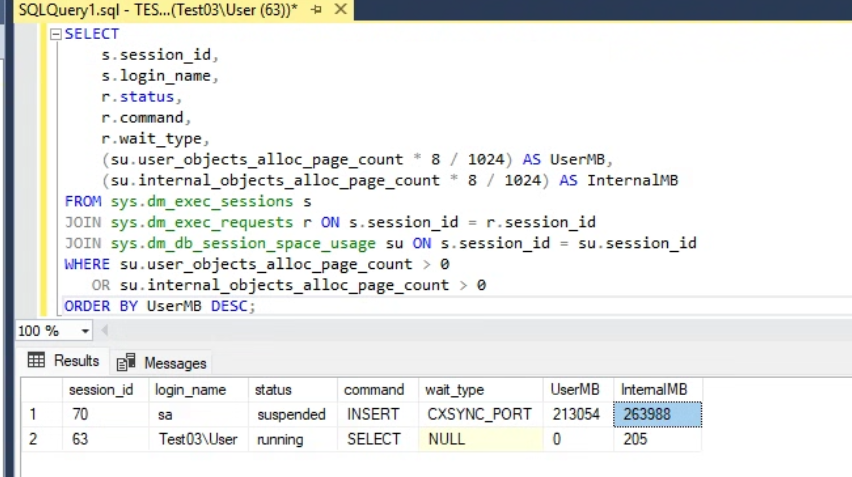
На этом этапе расследование стало предметным. Одна из сессий выполняла операцию `INSERT`, находилась в состоянии `suspended` и успела накопить колоссальный объём `internal objects` — на скриншоте видно значение порядка 263 988 МБ. Это уже не локальная просадка, а прямой путь к переполнению tempdb и остановке соседних операций.

Что это означало на практике
Сам по себе факт роста tempdb ещё не отвечает на вопрос о причине, но даёт хороший технический вывод: отчёт строил слишком тяжёлый промежуточный набор данных. Обычно так происходит, когда в запросе одновременно сходятся широкие выборки, неудачные соединения, сортировки по большим наборам и дополнительные преобразования, которые SQL Server вынужден выносить во временные структуры.
Именно поэтому ошибка выглядела как нехватка места на диске, хотя по сути это был симптом неудачной логики отчёта. tempdb оказался не источником проблемы, а местом, где она стала заметна уже на уровне инфраструктуры.
Если один отчёт начинает пожирать tempdb сотнями гигабайт, проблему стоит искать не в размере диска, а в форме промежуточных данных и плане выполнения.
Выводы
В таких инцидентах особенно важно не останавливаться на первой очевидной гипотезе. Да, диск действительно был почти заполнен. Но реальная причина оказалась в том, что один отчёт генерировал чрезмерный объём временных и внутренних объектов в tempdb. Поэтому правильный путь — не просто очистить место, а разобрать сам запрос, сократить промежуточные наборы, проверить соединения и понять, где именно появляется взрывной рост данных.
Хорошая новость в том, что подобные истории диагностируются достаточно быстро, если идти от симптома к фактам: ошибка клиента, состояние диска, содержимое tempdb, затем конкретная сессия и уже после этого — анализ самого отчёта. Такой порядок почти всегда экономит время и спасает от хаотичных действий на боевом сервере.